Kubernetes EndpointSlice Mirroring: Skip It Wisely
Kubernetes EndpointSlice Mirroring: Skip It Wisely
Hey there, Kubernetes enthusiasts! Today, we’re diving deep into a fascinating, somewhat niche, but incredibly powerful aspect of Kubernetes networking:
Kubernetes EndpointSlice mirroring
and the
iendpointslice.kubernetes.io/skip-mirror
annotation. You might be wondering, “Why would I ever want to
skip
something Kubernetes does automatically?” And that’s a
fantastic
question, guys! The truth is, while Kubernetes is brilliant at managing your workloads and networking by default, there are always advanced scenarios where taking the reins yourself can lead to better performance, more efficient resource utilization, or simply enable unique architectural patterns that aren’t quite standard. Understanding when and how to
wisely
use this
skip-mirror
feature can be a game-changer for your cluster’s efficiency and complexity management. We’ll explore what EndpointSlices are, why mirroring happens, and critically, when it makes sense to tell Kubernetes to hold off on its default behavior. So, let’s roll up our sleeves and get into the nitty-gritty of making your Kubernetes environment even more tailored to your specific needs!
Table of Contents
Understanding Kubernetes EndpointSlices and Mirroring
To truly grasp why you might want to
skip mirroring
for
Kubernetes EndpointSlices
, we first need to get a solid handle on what these components actually are and their crucial role in your cluster’s networking. Think of
EndpointSlices
as the modern, more scalable evolution of the older
Endpoints
API object. In essence, they represent a group of network endpoints (IP addresses and ports) that a Kubernetes Service routes traffic to. When you create a Service in Kubernetes, it needs to know
where
to send incoming requests. This is where EndpointSlices come into play, mapping that Service to the actual running Pods that fulfill its function. Before EndpointSlices, all these mappings were lumped into a single
Endpoints
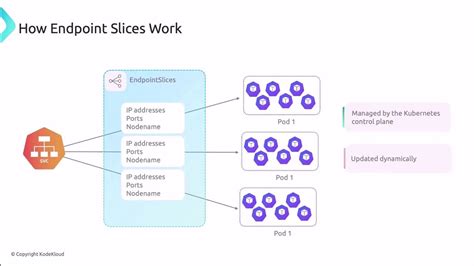
object, which became a significant performance bottleneck in large clusters with many services and thousands of pods. Imagine a service with thousands of backing pods – every change, every scaling event, would cause a massive single object update, putting a heavy strain on the API server.
EndpointSlices
gracefully solved this by splitting these endpoints into smaller, more manageable slices, improving the scalability and performance of the Kubernetes control plane significantly. This modular approach means updates are smaller and more targeted, reducing the load on the API server and
kube-proxy
instances across your cluster.
Now, about
mirroring
. By default, Kubernetes intelligently
mirrors
EndpointSlices. What this means is that for every
Service
you create, Kubernetes automatically creates and manages corresponding
EndpointSlice
objects. These mirrored EndpointSlices are typically owned by the Service controller and reflect the state of your Service’s backing Pods. When new Pods come up, old ones scale down, or Pods change their readiness status, the Service controller updates these mirrored EndpointSlices to ensure the Service always directs traffic to healthy, available targets. This automatic mirroring is
incredibly
useful and, frankly, essential for the vast majority of Kubernetes deployments. It ensures that your services are always up-to-date with the actual state of your application, providing seamless service discovery and load balancing within the cluster. It’s what allows your applications to find each other effortlessly without you having to manually configure network routes or IP addresses. The process is transparent, reliable, and a cornerstone of Kubernetes’ self-healing capabilities. So, why would anyone even
think
about disabling such a core and beneficial feature? Well, guys, while it’s fantastic for internal, Kubernetes-managed services, there are specific, advanced scenarios where this automatic mirroring might actually be counterproductive or even problematic. We’re talking about situations where you’re integrating with external systems, using custom controllers that manage endpoints outside the standard Kubernetes paradigm, or dealing with extremely large-scale clusters where every API object update has a measurable performance impact. In these niche cases, the default mirroring behavior can introduce unnecessary overhead or conflicts, making the
skip-mirror
annotation a powerful tool in your arsenal. It’s all about understanding the default behavior, appreciating its benefits, and then identifying those specific edge cases where a different approach makes more sense for your unique operational requirements. This nuanced understanding is what separates the casual user from the true Kubernetes architect.
Diving Deep into
iendpointslice.kubernetes.io/skip-mirror
Annotation
Alright, guys, let’s get down to the brass tacks: the
iendpointslice.kubernetes.io/skip-mirror
annotation. This little gem is your golden ticket when you need to tell Kubernetes, “Hey, I got this, don’t automatically create EndpointSlices for
this
particular Service.” What exactly does this
Kubernetes EndpointSlice mirroring skip annotation
do? When you apply
iendpointslice.kubernetes.io/skip-mirror: "true"
to a Service object, you are essentially instructing the Kubernetes Service controller to
not
create or manage EndpointSlice objects for that specific Service. This means Kubernetes will
not
automatically track the Pods selected by the Service’s
selector
and will
not
populate EndpointSlices with their IP addresses and ports. The Service will still exist, and its ClusterIP (if it’s a ClusterIP Service) will still be assigned, but it won’t have any backing endpoints
managed by the default controller
. This is a crucial distinction, as it implies that if you skip mirroring, you become responsible for managing the EndpointSlices or
Endpoints
objects that feed into that Service. Typically, this is done via a
custom controller
or an operator that has specific knowledge of external systems or custom logic for determining service endpoints. Without such a custom mechanism, your Service will essentially be a black hole – it exists, but traffic sent to it won’t have anywhere to go because there are no EndpointSlices telling
kube-proxy
where the actual Pods are. It’s a powerful override, but one that comes with the significant responsibility of manually, or programmatically, providing endpoint information.
So,
when to use this powerful annotation?
This isn’t something you’d slap on every Service, obviously. It’s primarily designed for
advanced deployments
and
integration scenarios
where Kubernetes’ default behavior doesn’t align with your architectural needs. One prime example is when you’re integrating a Kubernetes Service with an
external service
or system that exists outside your cluster’s native Pod ecosystem. Perhaps you have a legacy database running on a VM, or a managed cloud service, or even another Kubernetes cluster, that you want to expose via a Kubernetes Service. In such cases, the Service’s
selector
won’t match any internal Pods, and Kubernetes’ automatic mirroring would be pointless or even try to incorrectly find non-existent Pods. By skipping mirroring, you can then manually create an
EndpointSlice
(or the older
Endpoints
object, though
EndpointSlice
is preferred for scalability) that points to the
external IP address and port
of your target. Another compelling use case involves
custom network controllers
or
service mesh solutions
that take over the responsibility of endpoint management. These controllers might have their own sophisticated logic for discovering and managing service endpoints, potentially pulling information from external configuration management systems, DNS, or other service discovery mechanisms. In such environments, allowing the default Kubernetes controller to
also
manage EndpointSlices for the same Service could lead to conflicts, race conditions, or unnecessary overhead as both systems try to reconcile the same state.
By skipping mirroring
, you hand over complete control of endpoint population to your custom solution, ensuring a single source of truth and preventing conflicts. It also comes in handy for
performance optimization
in extremely large clusters where the sheer number of Pods and Services leads to a massive volume of
EndpointSlice
updates. If you have custom, highly optimized methods for endpoint discovery that reduce API server load, this annotation allows you to leverage them. Remember, applying this annotation requires careful consideration and a clear plan for how you will
programmatically manage the EndpointSlices
for the affected Service. It’s an escape hatch, not a default configuration.
How do you apply it? It’s straightforward, guys! You add it as an annotation to your Service manifest. Here’s a quick example:
apiVersion: v1
kind: Service
metadata:
name: my-external-service
annotations:
iendpointslice.kubernetes.io/skip-mirror: "true"
spec:
type: ClusterIP # Or NodePort, LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 8080
# IMPORTANT: No selector here, as Kubernetes won't be finding pods for us
# If you *do* include a selector, it will simply be ignored by the default controller
# when skip-mirror is true. It's often best to omit it for clarity.
After applying this Service, you would then need to
manually create
an
EndpointSlice
object that links back to
my-external-service
and provides the actual IP addresses and ports. For instance:
”`yaml apiVersion: discovery.k8s.io/v1 kind: EndpointSlice metadata: name: my-external-service-manual labels:
kubernetes.io/service-name: my-external-service
addressType: IPv4 endpoints:
- addresses: [
